ПОИСКОВЫЕ СИСТЕМЫ:
ПОЛЕ БОЯ - СЕМАНТИКА
Дмитрий ЛАНДЭ
dwl@visti.net
Феномен десятилетия
В настоящее время информационные ресурсы Сети составляют свыше десятка миллиардов документов (Web-страниц), к которым возможен свободный доступ любого пользователя. Естественно, для того, чтобы найти необходимую информацию и этой крупнейшей распределенной полнотекстовой базе данных необходимо использовать самые мощные ИПС. Такие системы существуют и конкурируют друг с другом на современном рынке информационных технологий.
Мы стали свидетелями интересного явления: за 10 лет мало кому известный полнотекстовый поиск стал повседневным инструментом миллионов людей, использующих такие системы-бренды, как Altavista, Google, Alltheweb, Yahoo, каждая из которых охватывает свыше миллиарда документов. При этом далеко не все лидеры информационных технологий десятилетие назад осознали эту тенденцию. "Недостаточные инвестиции Microsoft в технологию Интернет-поиска были непростительной ошибкой компании, но она работает над тем, чтобы наверстать упущенное. Говорят, что Microsoft успевает везде, но вот вам пример того, где мы не успели", - заявил CEO корпорации Стив Баллмер, выступая перед аудиторией менеджеров по маркетингу и представителей СМИ на пятой ежегодной конференции Microsoft по рекламе в Редмонде. Microsoft с трудом протискивается на одну из самых оживленных территорий в вебе. Она упорно старается наверстать упущенное, но пока отстает от своих главных конкурентов. При этом Баллмер заявил, что в ближайшие 12 месяцев команда разработчиков Microsoft должна предложить поисковую технологию первого поколения.
Вместе с тем, ситуация на рынке поисковых систем не простая - она отражает принцип новой экономики: здесь не может быть вторых ролей. Или система - лучшая в мире, или ей никто не будет пользоваться. Система должна найти свою нишу в задаче максимального удовлетворения запросов пользователей - быть самой полной, самой демократичной, самой интеллектуальной или самой локализированной.
Характеристики поисковых систем
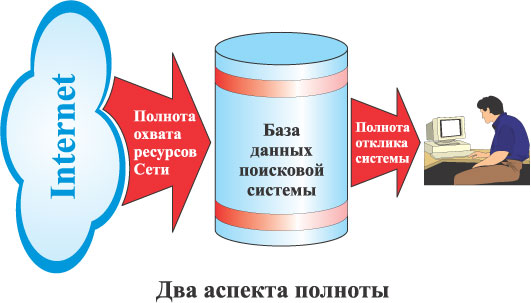
Основополагающими характеристиками информационно-поисковых систем является полнота и релевантность результатов поиска. Полнота поиска тесно связано с оперативностью охвата информации системой. Созданная однажды база данных Интернет-ресурсов является "слепком" состояния Сети в конкретный момент. Если эта база не будет обновляться постоянно и оперативно, присутствующие в ней ссылки на документы станут мертвыми. Кроме того, отсутствие оперативности, обновления баз данных не позволит пользователю отслеживать последние изменения в его предметной области.
Кроме характеристик полноты и релевантности для пользователей ИПС, большое значение имеют такие характеристики, как скорость обработки запросов, получения отклика от системы, достоверность отклика (например, оцениваемая по ее источникам), а также дополнительные сервисы - возможность нахождения документов, подобных уже имеющимся (like this), возможность подключения автоматических переводчиков и, конечно же, возможность уточнения запроса непосредственно после выполнения процедуры поиска.
Сегодня информации в Сети появляется больше, чем ее успевают проиндексировать поисковые системы. Поэтому идет жесткая конкурентная борьба, связанная с этим аспектом. Ведущими по охвату информационных ресурсов Интернет являются поисковые системы Google и Alltheweb. Вместе с тем, даже эти системы охватывают всего лишь третью часть существующих Web-страниц. Количество поисковых серверов, охватывающих Интернет, а не отдельные его части, ограничено несколькими десятками, лидерами в которых являются такие, как:
- http://www.google.com
- http://www.alltheweb.com
- http://www.altavista.com
- http://www.yahoo.com
- http://www.msn.com
- http://www.aol.com
- http://www.lycos.com
Среди российских поисковых серверов особого внимания заслуживают три - это Яндекс (http://www.yandex.ru), Рамблер (http://www.rambler.ru) и Апорт (http://www.aport.ru). В Украине две лидирующих поисковых системы - МЕТА (http://meta.ua/) - по стабильной части украинского сегмента Сети и UAport (http://uaport.net/) - по новостной части.
Полнота охвата ресурсов Сети - это один из двух главных аспектов характеристики полноты сетевой информационно-поисковой системы. Второй аспект связан с полнотой информации, предъявляемой пользователю по его запросу. Если предположить, что по запросу пользователя Q в базе данных находятся Р (при Р ( 0) документов, соответствующих этому запросу, а предъявлено для просмотра всего N документов, то полнота системы определяется по формуле: П=(N/P)x100%. В случае, если П оказывается больше 100%, очевидно, что пользователю выдано минимум N-P документов, не соответствующих его запросу, т.е. нерелевантных.
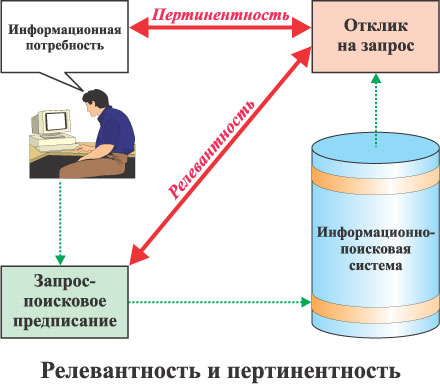
Под релевантностью понимается формальное соответствие информации, выдаваемой системой, запросу. Если по запросу пользователя получено N документов, представляющих собой объединение двух множества документов: соответствующих запросу (пусть их количество - N1), и не соответствующих (их количество - N2), т.е. N = N1+N2. Тогда релевантность, как степень соответствия, определяется по формуле: Р = (N1/N)x100%, а шум - по формуле: S = (N2/N)x100% = 100% - P. Это определение характерно для формальной релевантности, однако, на практике используется другое, неформальное понятие - пертинентность.
Пертинентность
Для пользователя пертинетность, соотношение объема полезной для него информации к общему объему полученной информации, имеет решающее значение. При этом следует учитывать, что формальный запрос к системе является предметом творческого осмысления информационной потребности и не всегда точно отражает последнюю. Неумение большинством пользователей правильно формулировать запросы и получать приемлемые объемы отклика породило в конце 20 века мнение об Интернет, как об огромной информационной свалке. Достижение высокой пертинентности - основное поле конкурентной борьбы современных поисковых систем. Именно для максимального удовлетворения информационных потребностей пользователей информационно-поисковые системы сегодня максимально интеллектуализируются - получили широкое практическое применение теории и методы семантических сетей, контент-анализа и глубинного анализа текстов (Text Mining).
Запросы пользователей
Казалось бы, с развитием технологических возможностей, современные поисковые системы должны обеспечить гарантированное нахождение информации, однако "ленивые" пользователи все же, очень часто не довольны качеством их работы. Основная масса пользователей не хочет прикладывать особых интеллектуальных усилий при формировании критериев поиска. Удивительно низким оказывается процент использования запросов, усложненных хотя бы одним логическим или контекстным оператором. Около 80 % запросов состоят из одного или двух слов. Если и используются операторы, то это в основном булевы AND и OR. Доля использования операторов контекстной близости и логического отрицания (NOT) не превышает 1-2%. В то же время, реализация отработки сложных запросов (которых пока не более 20%) и определяет эффективность использования времени, проводимого пользователем в Интернет.
Для ввода сложных запросов требуется использование булевых и контекстных операторов, скобок, указание полей и т.п., что недоступно для среднестатистического пользователя. Поисковые службы обычно создают два интерфейса - простой (по умолчанию) и расширенный (называемый в разных системах детальным, мощным или профессиональным), однако главная задача коммерческих поисковых служб как раз и заключается в удовлетворении информационных потребностей среднестатистического пользователя.
Назовем лишь некоторые возможности языков запросов наиболее популярных систем - возможности которые есть в распоряжении пользователей, но которые используются в очень небольшой части. Во всех современных системах реализованы булевы операторы AND, OR и NOT, а также работа со скобками. Однако в двух из них - AltaVista и Excite оператор NOT записывается в виде "AND NOT", - таким образом подчеркивается его бинарность (в математической логике оператор NOT в чистом виде - унарный). В режимах простого поиска булевы операторы реализуются не всегда указанием их в явном виде. Например, во многих поисковх системах пробел между словами запроса по умолчанию воспринимается как оператор AND (Allthenews, Google, META и UAport). В то же время при указании опций типа "any of the words", пробел в таких системах воспринимается как OR. Кроме тог, в Alltheweb допускается использование операторов "+" и "-" перед словами фактически как синонимов операторов AND и NOT, соответственно. Точно так же используются эти операторы в AltaVista, Excite, Lycos и Апорт. Большинство профессиональных поисковых систем обеспечивает выполнение операций контекстной близости, одна из реализаций которой - поиск выражений в кавычках. В системе Яndex режим контекстного поиска называется "поиском с расстоянием". В общем виде ограничение по расстоянию задается выражением вида "/(n m)", где n - минимальное, а m - максимальное допустимое расстояние. В системе Апорт существует два вида ограничения по расстоянию: в словах "wN(...)", где N - число слов и в предложениях "sN(...)", где N - число предложений.
Можно отметить, что у самой популярной сегодня системы Google - самый лаконичный набор операторов - "+", OR и "-" и реализована возможность поиска по фразам в кавычках.
Поиск по параметрам
Отдельного рассмотрения заслуживает возможность поиска по параметрам документов, которая позволяет ограничивать диапазон поиска значениями URL, датам, заглавий и т.п. Чаще всего выйти на возможность поиска по параметрам можно из режима расширенного поиска. В режиме расширенного поиска для ввода значений отдельных параметров предлагается весь диапазон возможностей Web-интерфейса.
Например, в системе Alltheweb в за просах можно указать параметры, обеспечивающие поиск по таким параметрам: URL (например, по запросу "url:energ" будут найдены документы, в URL которых присутсвует строка "energ"), ссылки на страницы сайтов ("link:"), доменные имена (например, "site:ua" обеспечит нахождение документов из украинского домена), заголовки ("title:"). В этой системе допустим поиск, кроме всех вариантов текстовых файлов, еще трех типов файлов - PDF, Ms Word, Flash.
В системе AltaVista присутствуют все приведенные для Alltheweb возможности (параметру "site:" в AltaVista соответствует "host:"), кроме того, в режиме расширенного поиска обеспечивается поиск по датам (с явным указанием "с...- по...", либо указанием тапа "искать за последние 8 месяцев"). Этот режим в системе традиционно называется "Web-археологией".
В Google обеспечивается поиск по сайту ("site:"), определение ссылок на сайт ("admission site:"), поиск по ценам, например "DVD player $250..350", странам, датам, доменам и т.д. В поле ввода запроса можно вводить и арифметические выражения, используя интерфейс Google как калькулятор, что, конечно же, подчеркивает своеобразность данной системы (например, по запросу "4^2" будет выведен результат 16).
Профессиональные запросы к традиционным системам
Традиционные системы пакетного поиска, обеспечивающие, например, рассылку результатов по электронной почте не предполагают интерактивного взаимодействия с конечным пользователем, поэтому им присуща полнота, которая сродни избыточности.
Так профессиональный запроса к системе "Интегрум" по теме "Услуги святи", выглядит следующим образом:
"услуги связи" или "междугородные переговоры" или "телефонные переговоры" или "мобильная связь" или "фиксированная связь" или "сотовая связь" или "сотовый оператор" или "средства связи" или "телефонная связь" или "спутниковая связь" или "космическая связь" или GPS или ростелеком или связьинвест или госкомсвязь или госкомтелеком или госсвязьнадзор или телекоммуникации или электросвязь или АТС или ГТС или минсвязи или "министерство связи" или "волоконно-оптическая линия связи" или ВОЛС
В системе InfoStream для реализации точной рассылки сообщений по теме "Мобильная связь" применяется такой запрос:
(((мобильн~связ) | (мобiльн~зв'яз) | (сотов~связ) | (стiльник~зв'яз) | (беспроводн~связ) | (бездрот~зв'яз) | (бесперебойн~связ) | (безперебiйн~зв'яз) | j2me]| ems]| 3g]| gprs]| ggsn]| sgsn]| sms]| mms]| ems]| bluetooth]| mms]| tdma]| multipoint]| pcs]| cdma]| ofdm]| vpn]| wap]| umts]| gsm)&((моб~телефон)| (стiльник~телефон)| (сотов~телефон))) ! this.is
Вместе с тем, очевидно, что для работы в режиме он-лайн такаие запроси неприемлемы. Пользователь желает ввести 1-2 слова и получить то, что ему не обходимо. Тут на помощь могут прийти только интеллектульные, семантические методы.
Кластеризация
В свое время создатели службы Oingo реализовали технологию выявления "смысла" слов путем построения обучаемой внутренней семантической сети. Сегодня наиболее интересной кажется технология, предлагаемая службой AltaVista (http://www.av.com/), обеспечивающая для реализации режима уточнения поиска (Refine Your Search) автоматическое определение классов, и последующую группировку (кластеризацию) откликов ИПС в соответствии ними. Например, в результате отработки запроса "network" (сеть) она предлагает следующие классы документов: Management; Solution; Catholic Church; Christian Organization; Domain Names; Blog; Economy; Moving; Project. В этой системе, как и в большинстве остальных, активизация соответствующего класса приводит к уточнению первоначального запроса.
Большинство же из современных интеллектуальных систем обеспечивает группировку своих откликов по заранее определенным классификаторам. Так система Vivisimo (http://www.vivisimo.com/) определила для запроса "network" такие классы: Solutions; Information Network; Security; Games; Organization; Computing; Project. Служба Lycos в режиме "Narrow Your Search" при этом определила такие классы: Carton Network; Dish Network; Food Network; Network Marketing; Home Shopping Network; Network Security. А система Google по этому же запросу выдала всего два класса: "Computers>Consultants>Network" и "Computers>Software>Operation System>Network".
Поиск по подобию
Если в результате поиска по запросу найдено избыточное количество документов, но при просмотре первых страниц результатов поиска найдено несколько пертинентных документов. Естественно, у пользователя возникает желание найти еще документы (или ссылки на них), сходные с ними по содержанию, не затрачивая интеллектуальных усилий на анализ и составление запроса.
Идя на поводу подобных желаний, многие ИПС реализовали опции "найти подобное", "похожие документы", "like this". Не всегда этот режим ведет к получению удовлетворительных результатов при целевом поиске, однако, иногда приводит к получению полезных документов, имеющих косвенное отношение к теме первичного запроса. Что означает "похожий документ", по каким критериям это определяется зачастую остается загадкой для пользователя. Один из подходов к ее решению может быть таким: каждое значимое по мнению системы слово ранжируется по какому-то критерию, из наиболее весомых слов автоматически формируется запрос, рассматриваемый как новый критерий поиска. Такой режим реализован во многих современных ИПС, например, на серверах Excite, Google и Яndex, а также в традиционных системах, использующих весовой критерий релевантности.
Ранжирование откликов
Средства повышения пертинентности в современных системах, помимо возможностей уточнения формулировки запросов, включает и весовые критерии, позволяющие ранжировать найденные документы и выдавать пользователю для просмотра наиболее весомые документы, либо вообще ограничиваться выдачей не более заданного числа наиболее весомых документов. В последнем случае, естественно, страдает полнота выдачи. Т.е. при этом полнота и релевантность являются антагонистическими характеристиками - чем выше релевантность, тем ниже полнота и наоборот. Проблеме релевантности, а особенно пертинентности уделяется большое внимание в современных системах. Так, например, служба Google реализовала алгоритмы достижения неформальной релевантности, и именно благодаря этому в свое время стала самой популярной системой в Интернет.
Ранжирование выдаваемых документов может выполняться по дате создания/обновления документа, по степени важности (многие системы оценивают важность документов по весовым критериям или по количеству ссылок на них, т.е. по цитированию). Ранжирование по дате имеет особое значение при поиске новостных сообщений средств массовой информации и информационных агентств.
Ранжирование по индексу цитируемости, аналогичное оценке значимости научных публикаций в традиционной научной среде впервые ввела Google, продемонстрировавшая эффективность такого подхода для Web-пространства.
Семантические методы
В последнее время в технологии поиска все чаще стали внедряться элементы контент-анализа, методологии возникших в конце XIX - начале ХХ вв. Эта методология, изначально ориентированная на применение в психологии и социологии, сегодня все чаще используется в разного типа автоматизированных системах. Различают количественный и качественный контент-анализ. Если качественный контент-анализ базируется на глубоком лингвистическом и семантическом анализе отдельных предложений и всего текста, то основой количественного контент-анализа являются статистические подходы.
В последнее время получили развитие такие направления контент-анализа, как "Data Mining" и "Text Mining", которые предполагают автоматическое выявление нового смысла из текстовых массивов, новых данных, феноменов, фактов - знаний. Все чаще возникают попытки привлечения методов контент-анализа, а точнее Text Mining в реальные поисковые системы. И эти попытки не умозрительны - они обусловлены объемами и темпами роста Сети. Во многие современные сетевые поисковые системы внедрены такие компоненты, как:
- автоматическая группировка документов, по определенному заранее классификатору;
- автоматическое определение новых, не заданных заранее классов, на основе неструктурированных или слабо структурированных документов;
- ранжирование документов по смысловой релевантности;
- выявление семантически подобных документов - поиск подобных документов на основе эталона;
- автоматический анализ и смысловое преобразование запросов пользователей.
"Сюжетный" подход
При поиске новостной информации всегда возникает задача нахождения и объединения в сюжетные темы документов, описывающих одни и те же события и ранжирования сюжетов по некоторым признакам, что должно обеспечить, не только выявления самой важной темы, но и "веерное" многоаспектное освещение всех наиболее значимых событий.
Эта задача, решаемая во многих системах с использованием различных подходов и алгоритмов. При этом неизменной остается технологическая цепочка: построение семантической сети из документов, кластеризация - автоматическое выявление наиболее взаимосвязанных групп, т.е. сюжетов, "взвешивание" этих сюжетов и наглядная визуализация самых важных из них. Основные факторы, влияющие на ранжирование по важности - оперативность информации и размер сюжетной цепочки. Под оперативностью понимается некоторая функция от времени публикации всех сообщений в сюжете, а размер сюжета отражает общий интерес к конкретной теме. Во всех этих подходах центральная задача состоит в отождествлении cообщений, относящихся к одному сюжету и выявление "непересекающихся" сюжетов.
Например, в системе Яндекс.Новости (http://news.yandex.ru) для этого строится матрица попарной близости документов, которая обрабатывается алгоритмом кластеризации с эмпирически подобранными параметрами (в частности, радиусом метрики близости). Для того, чтобы увеличить связность крупных сюжетов, в Яндекс.Новости дополнительно используется кластеризация второго уровня, обеспечивающая сбор атомарных кластеров в более крупные. В результате внедерения системы все сообщения в результатах поиска на сайте Яндекс.Новости сгруппированы по сюжетам, при этом ранжирование построено на стандартных для Яндекса принципах ранжирования сгруппированной выдачи. Оно основано на числе и ранге новостей внутри новостных сюжетов, при этом ранг одной новости определяется как ее свежесть с учетом приоритетов текстуального совпадения.
В системе InfoStream (http://infostream.ua) тематическая близость документов определяется на основе нормированных последовательностей наиболее весомых ключевых слов, входящих в каждый документ. Последовательности подобных (с определенным коэффициентом близости, превышающий некоторый установленный эмпирически) документов образуют цепочки. При этом каждый документ попадает в какую-нибудь цепочку, в крайнем случае, состоящую только из него самого. Затем цепочки взвешиваются по длине и оперативности, после чого пользователю предъявляется определенное количество самих важних тематических сюжетов. Для репрезентации сюжетной цепочки, заголовки документов также взвешиваются относительно ключевых слов, соответствующих сюжету, а затем из всех заголовков выбираются наиболее "весомые" для отображения.
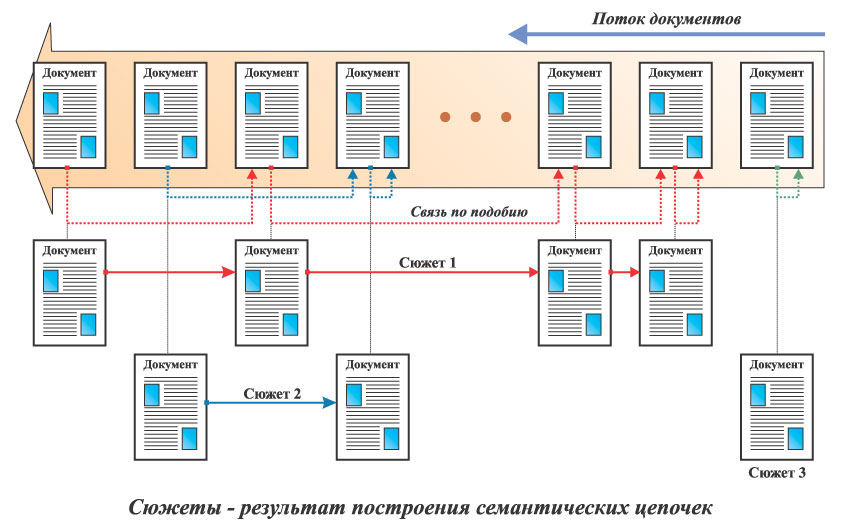
Следует обратить внимание, что задача автоматического построения качественных тематических сюжетов на основе потоков сетевой новостной информации сегодня практически решена. Например, полностью автоматические средства системы InfoStream, обрабатывая поток новостной информации, превышающий 20000 документов в сутки, обеспечивают полноту свыше 80% и точность около 95%.
Тернистый путь прогресса
Синтаксис запросов к популярным поисковым системам в последнее время значительно упростился, вместе с тем, качество откликов постоянно улучшается, несмотря на лавинообразный рост ресурсов Сети.
Традиционные подходы к поиску, основанные использовании логических операторов потерпели крах одновременно с бумом веб-технологий. Первые скрипки в поисковых системах стали играть не инструменты индексирования баз данных и организации логического поиска, а новые семантические алгоритмы. Можно признать, что пионером в этом стала компания Google, поставившая на ранжирование выдачи и алгоритмы, основанные на цитируемости.
Незавидна роль традиционных систем искусственного интеллекта в этой "семантической революции". Системы, основанные на базах знаний в большинстве своем не выдержали силы потока Интернет-информации. При этом речь идет не столько об объемах, сколько о политематичности и динамике, т.е. о постоянном обновлении информации, которое к тому же не имеет очевидной тематической направленности и регулярности.
При этом возник новый класс систем, который все же позволяет справляться с "проблемой размерности" Сети. Сегодня можно рассматривать как один из удивительных феноменов тот факт, что содержательные, семантически наполненные результаты формируются без непосредственного привлечения методов искусственного интеллекта, объемных баз знаний и даже экспертов как таковых, а путем использованием частотно-лингвистических и эвристических методов. И сегодня эффективно работают в основном системы, базирующиеся именно на таких методах.
|

 23.02.2015
23.02.2015

