|
Журнал "Cети и бизнес" N 1, 2001
Феномены современных информационных потоков
Дмитрий Ландэ,
Андрей Литвин
Информационный центр "ЭЛВИСТИ"
Восемь феноменов контент-анализа и контент-мониторинга
выявили авторы статьи, анализируя современное состояние
информационных потоков, методов их обработки и анализа.
Одной из главных особенностей нашего времени, безусловно, является
постоянный рост темпов производства информации (закон экспоненциального роста
информации). Кроме механического увеличения объемов информации до масштабов,
которые делают невозможным их непосредственную обработку, эта ситуация вызывает
целый ряд специфических проблем, связанных с быстрым развитием информационных
технологий. Порой эти проблемы настолько неочевидны, что их можно рассматривать
как феномены. В этой статье будут рассмотрены некоторые из них с учетом
возможностей, которые появились благодаря развитию технологий обработки
информации.
Феномен 1.
Прогресс в области производства информации ведет к снижению общего
уровня информированности и порождает новые виды сетевых служб.
Количество новостийных сообщений, публикуемых в сети Internet во всем мире,
превышает 1000000 в сутки. Крупнейшие сетевые интеграторы новостей
обрабатывают ежесуточно десятки тысяч сообщений. Ситуация резкого роста темпов
производства информации породила ряд проблем:
непропорциональный рост "информационного шума" ввиду слабой
структурированности информации;
появление паразитной информации (невостребованной, получаемой в качестве
несанкционированных "приложений", например, к электронным письмам);
несоответствие формально релевантной (уместной, относящейся к делу) информации
действительным потребностям;
многократное дублирование информации (типичный пример - публикация одного и
того же сообщения в разных изданиях).
Вследствие этого традиционные информационно-поисковые системы постепенно
стали утрачивать свою актуальность. Причина этого не столько в физических
объемах информационных потоков, сколько в их динамике, т.е. в постоянном
систематическом обновлении информации, которое к тому же далеко не всегда имеет
очевидную регулярность. Охват, обобщение больших динамических информационных
массивов, непрерывно генерируемых в New Media, требует качественно новых
подходов. В качестве иллюстрации приведем лишь один факт: служба AltaVista уже
около полугода не обновляла свою базу данных Web-ресурсов.
Возникла необходимость создания новых сетевых служб, интегрирующих
информационные потоки.
Феномен 2.
Новые сетевые службы, охватывая порой в 1000 раз меньше источников,
значительно эффективнее решают проблемы пользователей.
Необходимость сетевой интеграции новостей несколько лет назад осознали
известные сетевые поисковые службы. На первых этапах они заключили соглашения с
такими крупнейшими информационными агентствами, как Reuters, Associated Press,
CNN и др., и стали предоставлять доступ в режиме поиска и просмотра новостийных
сообщений. Таким образом, у пользователя впервые появилась возможность
бесплатно находить и просматривать новости реального (а не только
"виртуального") мира в Сети. Например, старейший навигационный портал Yahoo!
создал службу Daily News (http://dailynews. yahoo.com), объединив информацию
нескольких десятков агентств и обеспечив графическое и мультимедийное
представление отдельных тематических областей.
Одним из первых серьезных интеграторов новостей в Сети стала служба
Northern Light Technology (http://www.nlsearch.com/). Этой службой создана и
постоянно пополняется "специальная коллекция", включающая статьи из более чем
7000 источников - журналов, газет, агентств, реферативных журналов.
В настоящее время получила развитие тенденция централизованного
информационного обслуживания интеграторов новостей ("интеграция интеграторов"
или создание "информационных прокси"). Например, Northern Light Technology
является клиентом одной из крупнейших служб сбора новостей - COMTEX
(http://www.comtexnews.net/), которая интегрирует ресурсы солидных источников,
среди них такие крупнейшие мировые информационные агентства, как Associated
Press, ИТАР-ТАСС, Синьхуа. Клиентами COMTEX являются также десятки новостийных
служб, среди которых OneSource, Screaming Media, Vertical Net, CompuServe и др.
Количество охватываемых источников информации практически у всех интеграторов
новостей в настоящее время не превосходит 10 тысяч. При этом следует отметить,
что проблему полноты новостийной информации такой подход позволил решить,
оставив, однако, нерешенной проблему создания обозримого объема такой
информации, необходимой пользователю (чаще всего аналитику).
Феномен 3.
Существующие сегодня механизмы интеграции новостей эффективны
только при наличии собственной развитой информационной службы.
Каждая интересующая пользователя тематика, например "банковская сфера" или
"экология", в сутки может охватывать тысячи документов, которые могут быть
доставлены пользователю всеми доступными средствами (электронной почтой,
доступом к авторизированной Web-странице, WAP-серверу или в виде
SMS-сообщений). Даже эксперту порой не хватает времени на просмотр одних лишь
заголовков. К решению этой проблемы существует несколько подходов.
Ограничение, к примеру, количества источников может привести к
одностороннему подходу к проблематике, заангажированности. Можно ограничиться
регионом, например Украиной, или сузить тематику. В любом случае речь идет о
потере полноты. Выход может быть найден только в средствах автоматизации
выявления наиболее важной составляющей в информационном потоке. Стала
актуальной задача применения мониторинга ресурсов, тесно связанного с
достаточно популярным в последние десятилетия контент-анализом. Именно это
перспективное направление развития систем сетевой интеграции рассматривается
сегодня многими экспертами как контент-мониторинг, появление которого вызвано
прежде всего задачей систематического отслеживания тенденций и процессов в
постоянно обновляемой сетевой информационной среде.
Контент-мониторинг - это содержательный анализ информационных потоков с целью
получения необходимых качественных и количественных срезов, который
производится постоянно на протяжении не определенного заранее промежутка
времени. Важнейшей теоретической основой контент-мониторинга является
контент-анализ, - понятие, достаточно "заезженное" социологами.
Метод контент-анализа
Контент-анализ начинался как количественно-ориентированный метод анализа
текстов для изучения массовых коммуникаций. Он был впервые применен в 1910
году социологом Максом Вебером (Max Weber) чтобы проэкзаменовать охват
прессой политических акций в Германии. Американский исследователь средств
коммуникации Гарольд Лассвелл (Harold Lasswell) в 30-40-е годы использовал
подобную методику для изучения содержимого пропагандистских сообщений
военного времени. В 1943 году Абрахам Каплан (Abraham Kaplan) увеличил фокус
контент-анализа от статистической семантики (значения текстов) политических
дискуссий до анализа значений символов (семиотики). Во время Второй мировой
войны популярность семиотики привела к использованию
качественно-ориентированного контент-анализа для изучения "идеологических"
аспектов в таких жанрах, как телевизионные шоу и коммерческая реклама. Ряд
современных исследований с применением методологии контент-анализа включают
наряду с анализом текста и анализом изображений.
С появлением средств автоматизации, текстов в электронном виде, начиная c
60-х годов, начальное развитие получил контент-анализ информации больших
объемов - баз данных и интерактивных медиа-средств. Традиционное
"политическое" использование современных технологий контент-анализа
дополнено неограниченным перечнем рубрик и тем, охватывающих
производственную и социальную сферы, бизнес и финансы, культуру и науку, что
сопровождается большим количеством разнородных программных комплексов. При
этом выделилось направление, получившее самостоятельное развитие - Data
Mining, не имеющее устойчивого русского термина-эквивалента.
Под Data Mining понимается механизм обнаружения в потоке данных интересных
новых знаний, таких как модели, конструкции, ассоциации, изменения, аномалии
и структурные новообразования. Большой вклад в развитие контент-анализа
внесли психологические исследования в области феноменологии, ведущая идея
которой заключается в обращении к каждодневному миру через различные явления
(phenomena) в фактических ситуациях. С феноменологией неразрывно связаны
имена ее основателя Эдмунда Хассерла (Edmund Husserl) и нашего современника
Амадео Джиорджи (Amadeo Giorgi).
Феномен 4.
Популярный сегодня "контент-анализ" не имеет однозначной трактовки.
Однозначная трактовка понятий необходима прежде всего в технических
системах. Развитие технологических систем невозможно без стандартизации. В
качестве примера можно привести операционную систему UNIX, определение
стандартов на которую в рамках ISO (POSIX) привело к преобладанию клонов этой
системы на серверных платформах.
Понятие же контент-анализа, имеющее корни в психологии и социологии, сегодня
пока не имеет однозначного определения. Это порождает ряд проблем, важнейшая из
которых заключается в том, что программные системы, построенные на основе
различных подходов к контент-анализу, будут несовместимыми. Приведем лишь
некоторые определения контент-анализа:
Контент-анализ - это методика
объективного качественного и систематического изучения содержания средств
коммуникации (Д. Джери, Дж. Джери).
Контент-анализ - это систематическая числовая обработка, оценка и
интерпретация формы и содержания информационного источника (Д. Мангейм, Р.
Рич).
Контент-анализ - это качественно-количественный метод изучения документов,
который характеризуется объективностью выводов и строгостью процедуры и состоит
в квантификационной обработке текста с дальнейшей интерпретацией результатов
(В. Иванов).
Контент-анализ состоит в нахождении в тексте определенных содержательных
понятий (единиц анализа), выявлении частоты их встречаемости и соотношения с
содержанием всего документа (Б. Краснов).
Контент-анализ - это исследовательская техника для получения результатов
путем анализа содержания текста о состоянии и свойствах социальной
действительности (Е. Таршис).
Большинство из приведенных определений конструктивны, т.е. процедурны.
Из-за разных начальных подходов они порождают различные, а порой и
противоречащие друг другу алгоритмы. Принятые в современной литературе
различные подходы к пониманию контент-анализа поддаются полностью оправданной
критике. Так, высказываются сомнения в информационной насыщенности частотных
характеристик в плане определения элементов, весомых с точки зрения содержания.
Также подчеркивается игнорирование роли контекста. Однако, несмотря на
многообразие трактовок контент-анализа, большое прикладное значение методологии
все же позволяет избежать многих противоречий. Объединение средств и методов,
их естественный отбор путем многократной оценки полученных результатов
позволяют выделять и подтверждать знания, выявлять фактическую силу и
полезность инструментария.
Диапазон методов и процедур, касающихся самого процесса контент-анализа, весьма
широк. К примеру, при подготовке исследования выполняются следующие действия:
- описание проблемной ситуации, поиск цели исследования;
- уточнение объекта и предмета исследования;
- смысловое уточнение понятий;
- эмпирическая интерпретация понятий;
- описание процедур регистрации свойств и явлений;
- предварительный целостный анализ объекта;
- определение общего плана исследования;
- определение типа выборки, и т.д.
Методы сбора данных также многообразны:
- наблюдение;
- анкетный опрос;
- интервью;
- телефонный опрос;
- накопление совокупности писем;
- получение потока документов Сети.
Для отбора информации применяются такие методы:
- гнездовой;
- квотная выборка;
- неслучайная выборка;
- метод нетипичных представителей;
- метод "снежного кома";
- стихийная выборка;
- случайная;
- одно- и многоступенчатая;
- районированная (расслоение);
- систематическая и т.д.
В контент-анализе применяются такие математические методы, как
- дисперсионный анализ для выявления влияния отдельных, независимых факторов на
наблюдаемый признак;
- кластерный анализ для классификации объектов и описывающих их признаков;
- логлинейный анализ для статистической проверки гипотезы о системе одновременных
парных и множественных взаимосвязей в группе признаков;
- причинный анализ для моделирования причинных отношений между признаками с
помощью систем статистических уравнений;
- регрессионный анализ для исследования регрессионной зависимости между
зависимыми и независимыми признаками;
- факторный анализ для получения обобщенной информации о структуре связи между
наблюдаемыми признаками изучаемого объекта на основе выделения скрытых
факторов;
- корреляционный анализ для выявления зависимости между числовыми случайными
величинами, одна из которых зависит и от ряда других случайных факторов.
И наконец, теория информации, которая ранее находила свое основное
реальное применение в области техники передачи информации, сейчас становится
полезной и для анализа смысловых текстовых потоков. Энтропия с помощью
контент-анализа уменьшается весьма постепенно, но чем комплекснее
контент-анализ, тем заметнее переход от хаоса к порядку.
Демонстрационная система автоматического реферирования
Пример применения инструментария контент-анализа для автоматического
выявления ключевых слов и реферирования текста представлен на сайте
http://topwords.lgg.ru/atext/.
Анализатор текста проводит выявление и анализ списка ключевых слов,
построенного на основе введенного в окне документа (рис. 1). Список ключевых
слов ранжируется по весовому коэффициенту (рис. 2). Затем при необходимости
производится автоматическое реферирование текста, в результате чего
пользователь получает список наиболее значимых предложений исходного текста
- аннотацию (рис. 3).
 Рис. 1. Корневая страница системы автоматического реферирования текстов
Рис. 1. Корневая страница системы автоматического реферирования текстов
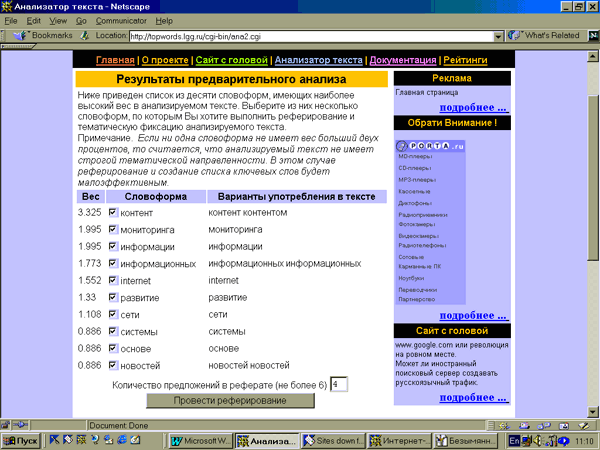 Рис. 2. Список ключевых слов по этой статье
Рис. 2. Список ключевых слов по этой статье
 Рис. 3. Аннотация как результат анализа
Рис. 3. Аннотация как результат анализа
Феномен 5.
Становление прикладных гуманитарных наук.
Интересной особенностью контент-анализа является и то, что эту методологию
до последнего времени связывали с определенной сферой человеческой деятельности
(политикой, психологией). Однако в настоящее время контент-анализ все шире
применяется во многих областях политической и экономической жизни, что
способствует обретению большого прикладного значения используемых в методологии
контент-анализа философских категорий, социологии и лингвистики.
Контент-анализ в рамках исследования электронных информационных потоков
является относительно новым направлением, предусматривающим анализ множества
текстовых документов (информационных лент) - результатов мониторинга
информационного пространства Сети.
Принято деление методологий контент-анализа на две ветви: качественную и
количественную. Основа количественного контент-анализа - частота появления в
документах определенных характеристик содержания. Качественный контент-анализ
основан на самом факте присутствия или отсутствия в тексте одной или нескольких
характеристик содержания. При этом приложение гуманитарных дисциплин, хотя и
носит вспомогательный характер, но охватывает очень широкий, до конца не
определенный спектр, в первую очередь в решении проблем, сопутствующих
качественному контент-анализу.
Методы проведения качественного контент-анализа основаны на том, что в
любой фазе количественного контент-анализа для оценок результатов может быть
привлечен эксперт. Качественный контент-анализ, таким образом, призван
обеспечить эксперта необходимыми средствами для выводов и дополнительных
результатов. Эксперт с помощью таких средств может выявить определенные
свойства части информации и проверить их применительно к общему текстовому
потоку, а общие свойства текстового потока распространить на его определенную
тематическую часть.
Процесс качественного контент-анализа состоит из трех основных стадий.
Первая - сведение большого количества текстовой информации к конечному числу
интегрированных блоков текста - единиц значения, которым ставится в
соответствие код для дальнейшей обработки этих блоков. Основными единицами
значения являются категории, последовательности и темы.
Вторая стадия качественного контент-анализа - реконструкция субъективных
составляющих текстового потока - системы значений, мышления, мнения, воззрений
и доказательств каждого источника текста. Для этого производится поиск
регулярных связей между единицами значения, характеризующими источник и условия
создания им текста.
Третья стадия - формирование выводов и обобщений путем сравнения индивидуальных
систем значений.
Современные технические, технологические и программные средства позволяют
в полном объеме формализовать ассоциативные знания путем создания большого
количества емких ассоциативных массивов с практически неограниченным числом
уровней вложения и формирования ассоциативно-статистических моделей.
Феномен 6.
Получение семантически наполненных результатов возможно и без
привлечения методов искусственного интеллекта.
Количественный контент-анализ, как правило, состоит из трех основных
этапов.
На первом этапе выделяются единицы анализа и переводятся в вид, приемлемый
для обработки (сегодня - в электронный вид).
Второй этап состоит в проведении подсчетов частот единиц анализа (этот этап
свойственен количественному контент-анализу) с применением различного
математического аппарата для выявления взаимосвязей между ними.
Суть третьего этапа заключается в интерпретации полученных результатов. При
этом без привлечения искусственного интеллекта, объемных семантических
формализаторов, даже экспертов как таковых, с использованием только частотных
методов могут быть получены содержательные, семантически наполненные
результаты.
В качестве примеров можно привести автоматически формируемые дайджесты,
автоматическое выявление взаимосвязи понятий (категорий), автоматическую
кластеризацию взаимосвязей для выявления наиболее важных из них, автоматическое
выявление "окраски" взаимосвязей, в простейшем случае - определение
принадлежностей взаимосвязей к положительным (группирующим) или отрицательным
(антагонистическим).
О взаимосвязи понятий
Таблица взаимосвязей понятий отражает одновременное присутствие двух понятий
в одних и тех же фрагментах текста (например, одновременно в одном
предложении, абзаце или документе). На Рис. 4 в качестве понятий
использовался ряд политических объединений Украины. Количество
обрабатываемых системой контент-мониторинга InfoStream документов из сети
Internet по тематике "Украина, политика" за 10 дней составило 4110. Кроме
того, на слайде представлена гистограмма встречаемости отдельных понятий.
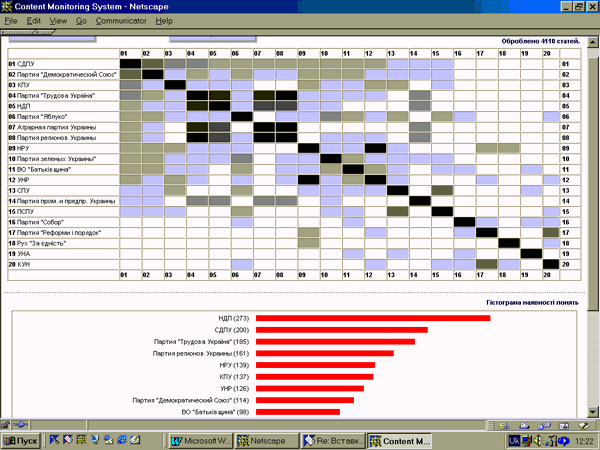
Рис. 4. Таблица взаимосвязей понятий на примере политических партий Украины
Феномен 7.
Автоматическое определение категорий возможно. Феномен создания
феноменов.
Одной из самых важных проблем в методологии контент-анализа является
процесс категоризации. Использование набора категорий задает концептуальную
сетку, в терминах которой анализируется текстовый поток. Одной из спорных точек
является допустимость формализации при выборе категорий и генерации такой
сетки. Советская наука, к примеру, не допускала такой формализации. Современные
же исследователи и разработчики признают полную или частичную формализацию при
большом объеме исследуемого потока. При этом огромное значение придается
человеческому фактору, выраженному в индивидуальных качествах исследователей,
уровне систематизированных знаний о мире и источников получения таких знаний.
Следует заметить, что сама информация рождается бессистемно. Без специальных
акций и программ ее порождает большое количество источников. Контент-анализ
призван обеспечить постоянный и надежный процесс систематизации.
Выявление категории предполагает также ее описание. В семантическом
подходе к описанию, при всей сложности и многообразии характеристик описания
присутствует их количественная оценка. Количество предпосылок для формализации
выявления и выбора категорий увеличивается с развитием современных технологий.
Современный информационный поток достиг таких масштабов, что сам является
источником всего необходимого для его дальнейшего исследования. В частности, он
практически содержит в себе весь словарь современного языка, мало того -
"готовые" специализированные словари: частотный, инверсный и прочие.
Исследование текстового потока, если он достаточно велик, возможно двумя
путями.
Первый путь - определение конечной, но очень большой, заведомо
избыточной, совокупности категорий для получения количественных данных о
встречаемости некоторых из них. При этом предполагается и автоматическая
кластеризация (классификация и группировка) изначально неупорядоченной
последовательности категорий и, соответственно, получение на ее основе новых
обобщенных категорий.
Второй путь - обнаружение в потоке с помощью количественных многоразовых
оценок новых знаний и последующая количественная квалификация их как категорий.
Это направление контент-анализа получило название "Data Mining" - дословно,
"раскопка данных". Таким образом, при любом из двух подходов происходит не что
иное, как генерация новых категорий - создание новых феноменов.
Феномен 8.
Контент-мониторинг - идея, которая материализовалась через десятки
лет после появления предпосылок.
В простейшем виде идею контент-мониторинга можно сформулировать как
постоянное, воспроизводимое во времени выполнение узко очерченного своими
задачами контент-анализа непрерывных информационных потоков. Подчеркнем, что
именно непрерывное воспроизведение во времени процесса обработки входных данных
является самой характерной чертой контент-мониторинга. Собственно
контент-анализ выступает здесь как методологическая составляющая, однако
контент-мониторинг имеет собственную проблематику и собственные пути решения
прикладных задач.
К теоретическим и методологическим предпосылкам появления систем
контент-мониторинга относятся:
- развитие теоретических основ контент-анализа, теория "раскопки данных" (Data
Mining);
- методы математической лингвистики;
- теория кластерного анализа.
К технологическим же предпосылкам относятся:
- появление и развитие алгоритмов и систем, построенных на основе методов
математической лингвистики;
- развитие сети Internet, ее технологий и информационных ресурсов;
- развитие и совершенствование технологий информационного поиска в
Internet-среде.
Пожалуй, лишь две последние технологические предпосылки можно условно
назвать "новинками". Что же тогда можно считать действительными причинами столь
большой задержки широкого внедрения подобных систем? Групп причин несколько:
социальная, опять же технологическая и экономическая.
К социальным причинам можно отнести желание определенных кругов
монополизировать контент-исследования (прежде всего, политические).
Технологические причины более очевидны - только в последние годы объем
электронных новостных сообщений достиг критической массы, покрывающей
практически все традиционные печатные СМИ. Например, объем украинских
Internet-новостей превосходит 5000 в сутки.
Экономические причины также понятны: стоимость развитых систем
контент-мониторинга составляет десятки и сотни тысяч долларов, и доступны они
далеко не всем экспертным центрам (речь не идет об элементарных агентах
новостей и push-каналах).
Методы контент-мониторинга, как эволюция идеологии контент-анализа,
получили большое развитие на территории бывшего СССР. Так, наиболее интересными
сегодня являются проекты М.Г. Крейнеса "Ключи от текста", Д.А.
Поспелова "Интерактивное выявление семантических структур текста", проект
"Оружие аналитика" компании "Инвента", проект "ВААЛ" и др.
Разработка систем контент-мониторинга проводится сегодня и в Украине.
Так, в Информационном центре "ЭЛВИСТИ" такая система создается на основе
технологии InfoStreamTM, обеспечивающей сбор и обработку информации из
сети Internet (в настоящее время обрабатывается около 20 000 документов в
сутки). Первая очередь этой системы контент-мониторинга решает задачи
формирования тематических информационных каналов, дайджестов, таблиц
взаимосвязей понятий, гистограмм распределения весовых значений отдельных
феноменов.
В ней на основании заданных конфигурационных характеристик (наборов слов,
сопровождающих определенные темы и понятия, количественных параметров)
исследуется текстовый поток. Он обрабатывается многократно, с добавлением
характеристик, полученных из самого потока. В результате генерируется, а затем
наглядно отображается обобщенная информация.
| 
 23.02.2015
23.02.2015

